Was versteht man unter einer Graphdatenbank?
Jeffrey Erickson | Senior Writer | 9. Januar 2026

Die Art und Weise, wie Graphdatenbanken Beziehungen zwischen Personen, Orten und Ereignissen sichtbar machen, macht sie zu einer wertvollen Technologie für zahlreiche Anwendungsfälle, darunter grafische Darstellung, Produktempfehlungen und Betrugserkennung. In jüngerer Zeit nutzen auch KI-Systeme Graphen, um Ergebnisse um zusätzlichen Kontext und mehr Details anzureichern. Werfen wir einen Blick darauf, wie Graphdatenbanken funktionieren und wie sich ihre besonderen Fähigkeiten optimal nutzen lassen.
Was versteht man unter einer Graphdatenbank?
Eine Graphdatenbank ist eine Datenbank, die speziell dafür entwickelt wurde, komplexe, miteinander verknüpfte Daten zu speichern und abzufragen. Sie speichert und stellt Entitäten als Knoten und Beziehungen als Kanten dar. Diese Graphstruktur ermöglicht es Anwendern, Graphanalysen durchzuführen, um komplexe Beziehungen zwischen Datenobjekten zu erkennen und eingehend zu untersuchen.
Es gibt eine Reihe von Graphdatenbanken auf dem Markt. Einige, wie Neo4j, sind spezialisierte Graphdatenbanken, die ausschließlich Graphdaten verarbeiten. Andere, darunter die Oracle AI Database, sind multimodale Enterprise-Datenbanken, die mehrere Datenmodelle unterstützen, einschließlich, aber nicht beschränkt auf Graphen. Im Gegensatz zu klassischen relationalen Datenbanken, die Daten in Tabellen speichern und Beziehungen über Joins abbilden, sind Beziehungen in Graphdatenbanken ein grundlegender Bestandteil der Datenbank. Sie stehen damit direkt für Abfragen und Analysen zur Verfügung, wie z. B. über Sprachen wie Cypher, Gremlin, PGQL und SQL.
Eine Graphdatenbank eignet sich besonders, um komplexe und dynamische Beziehungen zwischen Datenobjekten zu ermitteln. Das erklärt ihre Beliebtheit in Anwendungsfällen wie Routing- und Logistiksystemen, bei denen zahlreiche Faktoren in die Ermittlung optimaler Routen einfließen, oder in sozialen Netzwerken, in denen Empfehlungen einen detaillierten Blick auf das Beziehungsgeflecht aus Nutzern, Gruppen und Interessen erfordern. Darüber hinaus nutzen KI-Systeme Graphdatenbanken zunehmend, um mithilfe von Graph-RAG-Architekturen zeitnahere, relevantere und differenziertere Ergebnisse bereitzustellen.
Wichtige Erkenntnisse
- Graphdatenbanken bieten eine effektive Möglichkeit, Beziehungen und Abhängigkeiten zwischen Datenpunkten zu analysieren.
- Durch die Speicherung von Daten als Knoten und Kanten ermöglichen sie eine schnelle Navigation zwischen verknüpften Entitäten und den gezielten Abruf verknüpfter Informationen.
- Graphdatenbanken sind in zahlreichen Anwendungsfällen etabliert, darunter Anwendungen des Semantischen Web, Betrugserkennung, soziale Netzwerke sowie Empfehlungssysteme im Einzelhandel oder in der Unterhaltungsbranche.
- Zunehmend stützen sich auch moderne KI-Systeme mit Graph-RAG-Architekturen auf Graphdatenbanken, um differenziertere und präzisere Ergebnisse zu erzielen.
Graphdatenbanken einfach erklärt
Graphdatenbanken nutzen Graphmodelle, um Beziehungen in Daten darzustellen. Sie ermöglichen sogenannte Traversal-Abfragen, bei denen ein Datensatz entlang vorhandener Beziehungen durchlaufen wird, um (indirekte) Verbindungen zwischen Datenpunkten zu identifizieren. Anschließend wendet die Datenbank Graphalgorithmen an, um Muster, Pfade, Communities, Einflussfaktoren, Single Points of Failure und weitere Beziehungen zu erkennen. Die Stärke von Graphen liegt in ihrer Fähigkeit, unterschiedliche Datenquellen miteinander zu verknüpfen und daraus neue Erkenntnisse zu gewinnen – selbst in sehr großen und vielfältigen Datensätzen.
Graphalgorithmen sind speziell darauf ausgelegt, Beziehungen und Verhaltensmuster in Graphen zu analysieren. Dadurch lassen sich Zusammenhänge aufdecken, die mit anderen Methoden nur schwer oder gar nicht sichtbar sind. So können Graphalgorithmen beispielsweise ermitteln, welche Personen oder Objekte in sozialen Netzwerken bzw. Geschäftsprozessen besonders stark vernetzt sind. Zudem identifizieren sie Communities, Anomalien, wiederkehrende Muster sowie Pfade, die Personen oder zusammenhängende Transaktionen miteinander verbinden.
Um diese Erkenntnisse zu gewinnen, analysieren Algorithmen Pfade und Distanzen zwischen Knoten, also Datenpunkten, die Entitäten in einem Datensatz repräsentieren, sowie deren Relevanz und Ansammlung zu Clustern. Zur Bewertung der Relevanz betrachten die Algorithmen häufig eingehende Kanten, die Bedeutung benachbarter Knoten und weitere Indikatoren. Graphdatenbanken speichern diese Beziehungen direkt als Daten zusammen mit den Knoten selbst. Dadurch ermöglichen sie eine schnelle Navigation und den gezielten Abruf verknüpfter Informationen. Zudem bieten Graphdatenbanken ein flexibles Datenschema, sodass sich das Datenmodell flexibel an veränderte Beziehungen anpassen und weiterentwickeln lässt.
Funktionsweise von Graphdatenbanken
Graphdatenbanken speichern Informationen in Form eines Netzwerks aus Knoten, die Entitäten wie Bankkonten oder Überweisungen repräsentieren, und Kanten, welche die Beziehungen zwischen diesen Knoten abbilden. Bei einer Abfrage durchläuft die Datenbank diese vordefinierten Kanten von einem Knoten zum nächsten, um Muster und Pfade innerhalb der Daten zu erkennen.
Die folgende Abbildung zeigt ein einfaches Beispiel für eine Graphdatenbank im Einsatz. Sie veranschaulicht das bekannte Partyspiel „Six Degrees of Kevin Bacon“, bei dem Verbindungen zwischen Kevin Bacon und einem anderen Schauspieler über eine Kette gemeinsamer Filme hergestellt werden. Diese Bedeutung von Beziehungen macht das Spiel zur idealen Methode, um Graphanalysen zu veranschaulichen.
Man kann sich einen Datensatz mit zwei Knotenkategorien vorstellen: alle Filme aus Bacons Karriere und alle Schauspieler, die in diesen Filmen mitgewirkt haben. Mithilfe von Graphtechnologie führen wir anschließend eine Abfrage aus, die Bacon mit der Muppet-Ikone Miss Piggy verbindet. Als Ergebnis würden wir Folgendes erhalten:
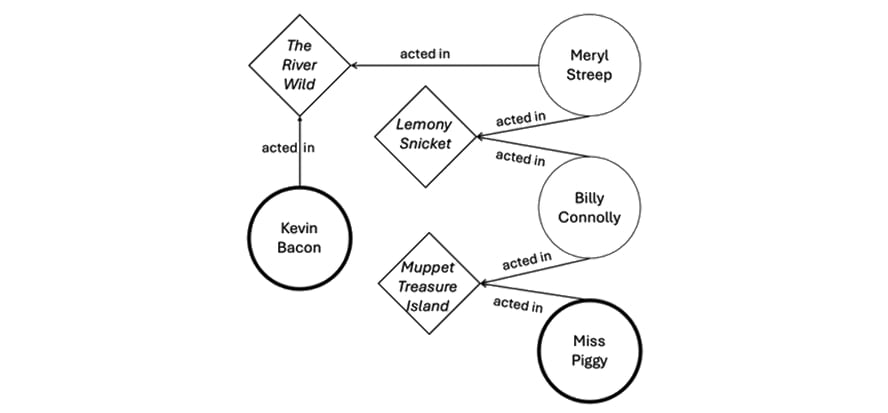
In diesem Beispiel umfassen die verfügbaren Knoten (Eckpunkte) sowohl Schauspieler als auch Filme, und die Beziehungen (Kanten) bedeuten „spielte in“. Von hier aus gibt die Abfrage die folgenden Ergebnisse aus:
- Kevin Bacon spielte in „Am wilden Fluss“ mit Meryl Streep.
- Streep spielte in „Lemony Snicket – Rätselhafte Ereignisse“ mit Billy Connolly.
- Connolly spielte in „Muppets – Die Schatzinsel“ mit Miss Piggy.
Graphdatenbanken können für dieses Beispiel viele unterschiedliche Beziehungen abfragen, zum Beispiel:
- „Was ist die kürzeste Verbindung zwischen Kevin Bacon und Miss Piggy?“
A: Analyse des kürzesten Pfades, wie im obigen Six Degrees-Spiel verwendet. - „Wer hat mit den meisten Schauspielern zusammengearbeitet?“
A: Die Degree-Zentralität würde den Schauspieler mit der höchsten Anzahl gemeinsamer Auftritte ermitteln. - „Wie groß ist der durchschnittliche Abstand zwischen Kevin Bacon und allen anderen Schauspielern?“
A: Die Closeness-Zentralität liefert ein Maß für die Vernetzung zwischen Schauspielern in der Filmindustrie.
Natürlich handelt es sich hierbei um ein deutlich unterhaltsameres Beispiel als die meisten realen Anwendungsfälle von Graphanalysen. Dieser Ansatz lässt sich jedoch auf nahezu alle Daten anwenden, also überall dort, wo große Datenmengen eine natürliche Vernetzung aufweisen. Zu den beliebtesten Einsatzgebieten von Graphanalysen zählen die Untersuchung sozialer und Telekommunikations-Netzwerke, die Analyse von Website-Traffic und Nutzungsmustern sowie die Auswertung von Finanztransaktionen und Konten.
Graphdatenbanken mit Graphen
Um einen Graphen zu erstellen, definieren Sie zunächst das Datenmodell, indem Sie Knoten und Kanten festlegen. Anschließend fügen Sie die Daten mithilfe einer Abfragesprache in die Graphdatenbank ein, zum Beispiel mit SQL bzw. PGQL von Oracle oder mit Open-Source-Sprachen wie Cypher oder Gremlin.
Graphdatenbanken und Graphanalysen
Datenbanken ermöglichen Graphanalysen, indem sie Algorithmen unterstützen, die Graphdaten traversieren, um Muster und Beziehungen zu erkennen, wie z. B. die Breitensuche (BFS, Breadth-First Search) und die Tiefensuche (DFS, Depth-First Search). Darüber hinaus verfügen Graphdatenbanken häufig über integrierte Funktionen für Graphanalysen, wie beispielsweise zur Berechnung von Zentralitätsmaßen und zur Community-Erkennung. Einige Datenbanken erlauben es Anwendern zudem, schnell Aktionen wie das Entfernen, Gruppieren, Erweitern und Fokussieren von Knoten und Kanten auszuführen, um Visualisierungen anzupassen und Beziehungen in komplexen Graphdaten zu untersuchen.
Die Vorteile von Graphdatenbanken
Da Graphdatenbanken die Beziehungen zwischen Datenpunkten in den Mittelpunkt stellen, ermöglichen sie eine effiziente Analyse komplexer Zusammenhänge und liefern mit deutlich geringerem Aufwand tiefere und aussagekräftigere Erkenntnisse. Zu diesen Vorteilen gehört Folgendes:
- Bessere Analyse von Netzwerken: Graphen identifizieren schnell Knoten mit hoher Aktivität oder großem Einfluss und decken Schwachstellen in Netzwerken auf. So lassen sich der Zustand eines Netzwerks oder einer Community präzise analysieren.
- Analyse in Sekundenbruchteilen: Graphdatenbanken speichern Beziehungen explizit, sodass Abfragen und Algorithmen die direkte Konnektivität zwischen Knoten nutzen können und Ergebnisse in Bruchteilen von Sekunden statt erst nach Stunden oder Tagen liefern. In traditionellen relationalen Datenbanken wären dafür zahlreiche und aufwendige Joins erforderlich.
- Breites Spektrum an Anwendungsfällen: Graphen ermöglichen es, Verbindungen und Muster beispielsweise in sozialen Netzwerken, IoT-Sensordaten, Data Lakes und Data Warehouses zu untersuchen und zu erkennen. Zudem analysieren sie komplexe Transaktionsdaten schnell für zahlreiche geschäftliche Anwendungsfälle, darunter Betrugserkennung im Bankwesen, das Aufdecken von Abhängigkeiten in Fertigungsprozessen sowie Empfehlungssysteme im Einzelhandel.
Wann Graphdatenbanken eingesetzt werden sollten
Die Fähigkeit, Beziehungen und Verbindungen zwischen Personen, Orten, Ereignissen, Finanzmitteln und vielen weiteren möglichen Datenpunkten schnell zu verstehen, ist für eine Vielzahl geschäftlicher und staatlicher Aktivitäten von entscheidender Bedeutung. Lassen Sie uns einige Beispiele betrachten, um zu verdeutlichen, warum das so ist.
Anwendungsfälle für Graphdatenbanken
Graphdatenbanken werden in vielen Branchen eingesetzt, wobei der gemeinsame Nenner die zentrale Rolle von Beziehungen zwischen Datenpunkten ist. Typische Anwendungsfälle sind unter anderem:
-
Analyse sozialer Medien: Soziale Netzwerke sind ein idealer Anwendungsfall, da sie aus vielen Knoten (Benutzerkonten) und multidimensionalen Verbindungen (Interaktionen in unterschiedliche Richtungen) bestehen. Eine Graphanalyse eines sozialen Netzwerks kann beispielsweise durch die Anzahl der Knoten verdeutlichen, wie aktiv die Nutzer sind. Welche Nutzer haben den größten Einfluss? (Dichte der Verbindungen). Wer weist das stärkste wechselseitige Engagement auf? (Richtung und Dichte der Verbindungen). Diese Informationen verlieren jedoch ihren Wert, wenn Bots sie künstlich verzerren.
Soziale Mediennetzwerke tun ihr Möglichstes, um Bot-Konten zu eliminieren, da diese sich fundamental auf die gesamte Nutzererfahrung auswirken. Glücklicherweise ist die Graphanalyse auch ein hervorragendes Mittel, um Bots zu identifizieren und herauszufiltern. In einem realen Anwendungsfall verwendete das Team von Oracle die Oracle Marketing Cloud, um Werbewirkung und Zugkraft von sozialen Medien zu bewerten – insbesondere zur Identifizierung von Bots. Das häufigste Verhalten dieser Bots bestand darin, Inhalte von Zielkonten erneut zu posten und dadurch deren Popularität künstlich zu erhöhen. Eine einfache Musteranalyse zeigte die Anzahl der Reposts sowie die Dichte der Verbindungen zu benachbarten Knoten. Natürlich populäre Konten wiesen dabei andere Beziehungen zu ihren Nachbarn auf als botgesteuerte Konten.
Diese Abbildung zeigt tatsächlich beliebte Konten.
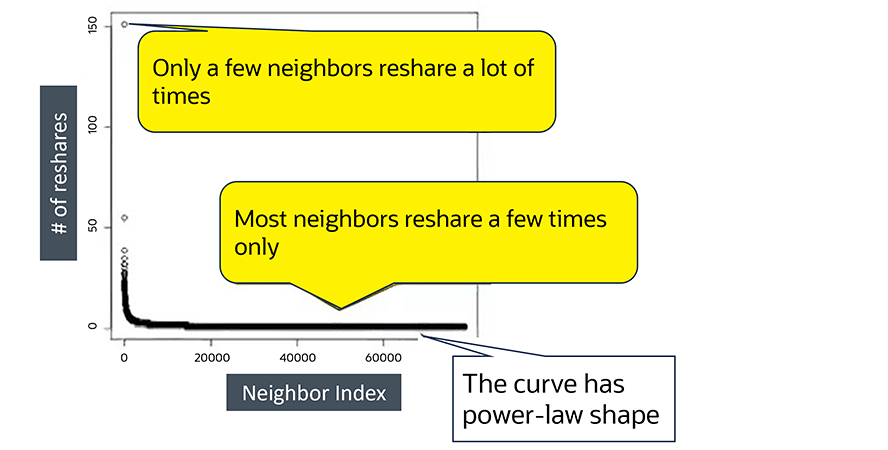 In einem einfachen Kurvendiagramm realer Social-Media-Konten teilen die meisten Nachbarn Inhalte nur wenige Male. Dieses Muster entspricht der typischen Form einer Power-Law-Verteilung.
In einem einfachen Kurvendiagramm realer Social-Media-Konten teilen die meisten Nachbarn Inhalte nur wenige Male. Dieses Muster entspricht der typischen Form einer Power-Law-Verteilung.Und diese Abbildung stellt das Verhalten eines Bot-unterstützten Kontos dar.
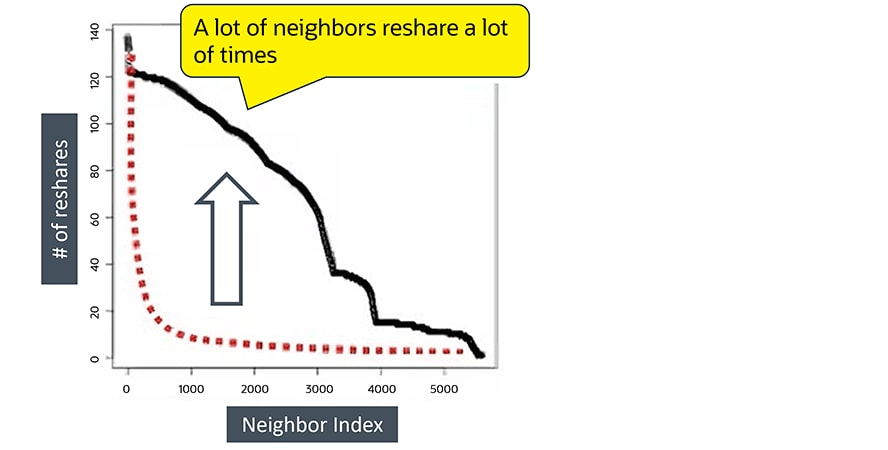 In einem einfachen Kurvendiagramm zur Darstellung der Aktivität von Bot-Konten lassen sich diese anhand einer deutlich höheren Anzahl von Nachbarn erkennen, die Inhalte vielfach weiterverbreiten.
In einem einfachen Kurvendiagramm zur Darstellung der Aktivität von Bot-Konten lassen sich diese anhand einer deutlich höheren Anzahl von Nachbarn erkennen, die Inhalte vielfach weiterverbreiten.Nachdem die Graphanalyse natürliche Muster von Bot-Mustern unterschieden hatte, konnten diese Konten einfach herausgefiltert werden. Darüber hinaus lassen sich weiterführende Analysen durchführen, um die Beziehungen zwischen Bots und erneut postenden Konten genauer zu untersuchen. Um zu verifizieren, ob die Bot-Erkennung auch korrekt war, wurden die markierten Konten nach einem Monat überprüft. Die Ergebnisse waren wie folgt:
- Gesperrt: 89 %
- Gelöscht: 2,2 %
- Noch aktiv: 8,8 %
Diese extrem hohe Quote sanktionierter Konten von 91,2 % zeigte die hohe Genauigkeit der Mustererkennung. Die Identifikation komplexer Muster hätte in einer klassischen relationalen Datenbank deutlich mehr Zeit in Anspruch genommen. Mit Graphanalysen ist dies hingegen schnell und effizient möglich.
Erkennung von Kreditkartenbetrug: Graphdatenbanken haben sich in der Finanzbranche als leistungsstarkes Tool zur Betrugserkennung etabliert. Trotz technologischer Fortschritte, wie etwa integrierter Chips in Karten, kommt es weiterhin zu Betrug. Skimming-Geräte (Geräte zum Ausspähen) können Daten von Magnetstreifen auslesen und stehlen. Diese Technik wird häufig an Orten eingesetzt, an denen noch keine Chip-Lesegeräte installiert sind. Sobald diese Daten gespeichert wurden, können sie auf eine gefälschte Karte geladen werden, um mit dieser Einkäufe zu tätigen oder Geld abzuheben.
Die Identifikation von Mustern ist häufig die erste Verteidigungslinie bei der Betrugserkennung. Erwartete Kaufmuster basieren auf dem Standort, der Häufigkeit, den Arten der Läden und anderen Faktoren, die zu einem Nutzer-Profil passen. Wenn etwas anomal erscheint, wie z. B. wenn sich eine Person normalerweise überwiegend in der San Francisco Bay Area aufhält und plötzlich spät in der Nacht in Florida einkauft, wird dies vom System als möglicher Betrugsversuch gekennzeichnet. Der dafür erforderliche Rechenaufwand wird durch Graphanalysen erheblich vereinfacht, da sie besonders gut darin sind, Muster zwischen Knoten zu erkennen. In diesem Fall werden die Knotenkategorien als Konten (Karteninhaber), Einkaufsorte, Einkaufskategorien, Transaktionen und Terminals definiert. So lassen sich natürliche Verhaltensmuster problemlos feststellen. Zum Beispiel könnte eine Person in einem bestimmten Monat Folgendes tun:
- In verschiedenen Tiergeschäften (Terminals) Tiernahrung (Kaufkategorie) erwerben
- An Wochenenden in einer bestimmten Region Restaurantbesuche bezahlen (Transaktionsmetadaten, Einkaufsorte)
- Reparaturwerkzeuge (Kaufkategorie) in einem örtlichen Baumarkt (Kontostandort, Kaufort) kaufen.
Bei der Betrugserkennung wird üblicherweise maschinelles Lernen, eingesetzt. Die Graphanalyse kann diese Aufgabe jedoch ergänzen, sodass dieser Prozess genauer und effizienter wird. Die Ergebnisse haben sich dank des Fokus auf Beziehungen als effektive Prädiktoren zur Identifikation und Kennzeichnung betrügerischer Datensätze erwiesen.
Erkennung von Geldwäsche: Graphdatenbanken können auch bei der Aufdeckung komplexerer Betrugsformen unterstützen. Grundsätzlich ist Geldwäsche einfach erklärt: Illegal erlangtes Bargeld wird weitergereicht, mit legitimen Geldern vermischt und anschließend in Sachwerte umgewandelt. Konkret beschreibt ein zirkulärer Geldtransfer das Vorgehen eines Kriminellen, der große Mengen betrügerisch erlangten Geldes an sich selbst überweist und dies durch eine lange, komplexe Kette scheinbar legitimer Transaktionen über „normale“ Konten verschleiert. Diese Konten werden häufig mit synthetischen Identitäten angelegt und weisen meist sehr ähnliche Informationen auf. Gerade deshalb eignet sich die Graphanalyse hervorragend, um den betrügerischen Ursprung offenzulegen. Zur Vereinfachung der Betrugserkennung kann ein Finanzunternehmen aus den Transaktionen zwischen Konten einen Graphen erstellen. Sobald dieser Graph vorhanden ist, reicht eine einfache Abfrage aus, um alle Kunden zu identifizieren, deren Konten sich gegenseitig Geld senden und dabei teilweise übereinstimmende Informationen wie E-Mail-Adressen, Anschriften oder Telefonnummern aufweisen.
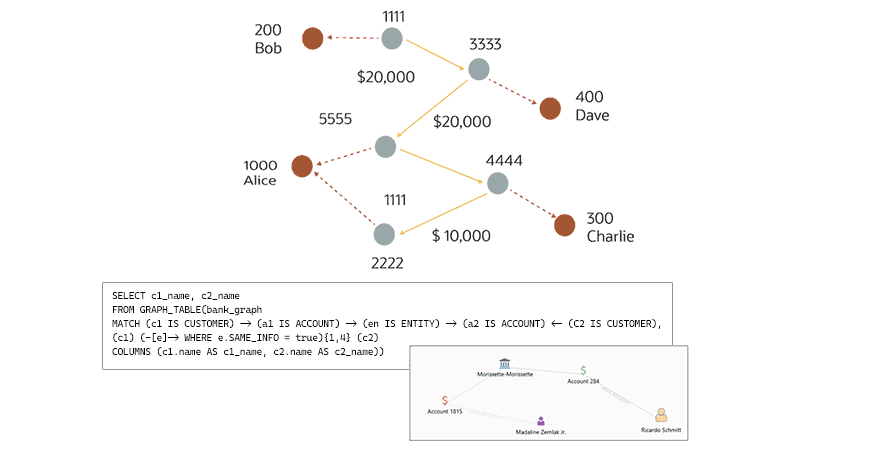 Ein Diagramm zur Veranschaulichung einer Graphdatenbankabfrage zur Erkennung von Geldwäsche zeigt eine visuelle Darstellung von Kunden und Konten, die durch Banküberweisungen miteinander verbunden sind, sowie den zugehörigen SQL-Code.
Ein Diagramm zur Veranschaulichung einer Graphdatenbankabfrage zur Erkennung von Geldwäsche zeigt eine visuelle Darstellung von Kunden und Konten, die durch Banküberweisungen miteinander verbunden sind, sowie den zugehörigen SQL-Code.Dieses Beispiel zeigt, wie bereits eine einfache Abfrage in einer Graphdatenbank zur Aufdeckung von Geldwäsche beiträgt, indem Kunden identifiziert werden, deren Konten sich gegenseitig Gelder überweisen und dabei ähnliche Informationen aufweisen.
Die Zukunft von Graphdatenbanken
Graphdatenbanken und Graphtechniken haben sich im letzten Jahrzehnt parallel zum Wachstum von Rechenleistung und Datenvolumen stark weiterentwickelt. Dabei ist zunehmend klar geworden, dass sie ein zentrales Tool für die Analyse einer neuen, komplexen Welt von Datenbeziehungen darstellen. Während Unternehmen und Organisationen ihre Daten- und Analysefähigkeiten weiter ausbauen, wird die Fähigkeit, Erkenntnisse aus immer komplexeren Zusammenhängen zu gewinnen, Graphdatenbanken zu einem unverzichtbaren Bestandteil für heutige Anforderungen und zukünftigen Erfolg machen.
So wählen Sie die richtige Graphdatenbank aus
Es gibt zwei gängige Modelle von Graphdatenbanken: Property-Graphs und RDF-Graphs, die häufig auch als Wissensgraphen bezeichnet werden. Bei der Auswahl des passenden Modells ist es hilfreich zu beachten, dass sich der Property-Graph auf Analysen und Abfragen konzentriert, während das RDF-Modell den Schwerpunkt auf Datenintegration und semantischer Suche legt. Beide Diagrammtypen bestehen aus einer Sammlung von Punkten (Eckpunkten) und den Verbindungen zwischen diesen Punkten (Kanten). Wissensgraphen, die die Bedeutung und den Kontext der im Graphen identifizierten Beziehungen abbilden, gewinnen für künstliche Intelligenz zunehmend an Bedeutung.
Property-Graphs: Property-Graphs werden verwendet, um Beziehungen zwischen Daten zu modellieren und darauf basierend Abfragen sowie Datenanalysen durchzuführen. Ein Property-Graph besteht aus Knoten, die detaillierte Informationen zu einem Objekt enthalten, und Kanten, die die Beziehungen zwischen diesen Knoten darstellen. Sowohl Knoten als auch Kanten können Attribute haben, die als Eigenschaften bezeichnet werden und denen sie zugeordnet sind.
Dieses Beispiel stellt eine Gruppe von Kollegen und ihre Beziehungen als Property-Graph dar. Es zeigt, wie Kollegen miteinander zusammenarbeiten und sich leider auch untereinander zerstreiten können. Zusätzlich lassen sich Eigenschaften dieser Kollegen abbilden, wie z. B. ihre Rollen, die Städte, in denen sie leben, ob sie remote arbeiten oder ihre Zugehörigkeit zu bestimmten Abteilungen.
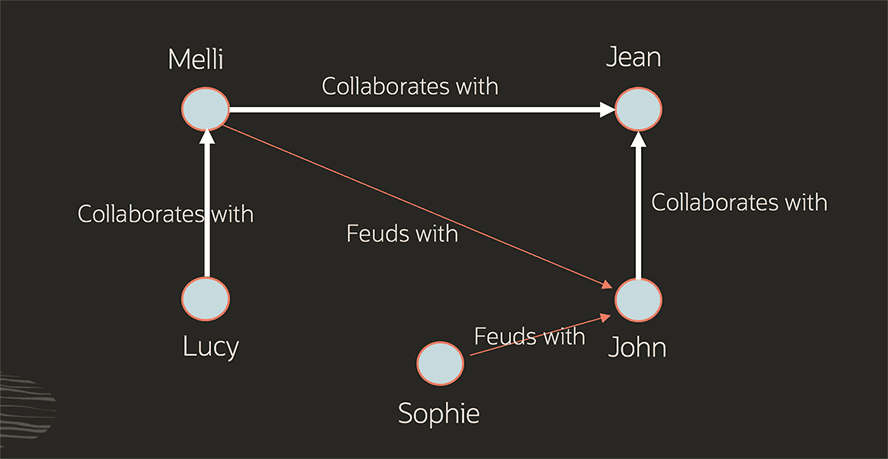
Aufgrund ihrer hohen Flexibilität werden Property-Graphs in zahlreichen Branchen und Bereichen eingesetzt, wie z. B. im Finanzwesen, in der Fertigungsindustrie, im öffentlichen Sicherheitsbereich und im Einzelhandel.
RDF-Graphs: RDF-Graphs (Resource Description Framework) folgen einer Reihe von Standards des World Wide Web Consortium (W3C), die zur Darstellung von Aussagen entwickelt wurden. Sie eignen sich besonders zur Abbildung komplexer Metadaten und Stammdaten. Häufig werden sie für Linked Data (verknüpfte Daten), Datenintegration und zunehmend auch für Wissensgraphen eingesetzt. Zudem können sie komplexe Konzepte innerhalb eines Fachgebiets darstellen oder eine reichhaltige Semantik sowie logische Schlussfolgerungen auf Basis der Daten ermöglichen.
Im RDF-Modell wird eine Aussage durch drei Elemente dargestellt: zwei Knoten, die durch eine Kante verbunden sind und Subjekt, Prädikat und Objekt eines Satzes repräsentieren. Diese Struktur wird als RDF-Triple bezeichnet. Jeder Knoten und jede Kante wird dabei durch einen Uniform Resource Identifier (URI) eindeutig identifiziert. Das RDF-Modell bietet eine Möglichkeit, Daten in einem Standardformat mit genau definierter Semantik zu veröffentlichen und so den Informationsaustausch zu ermöglichen. Regierungsstatistikagenturen, Pharmaunternehmen und Gesundheitsorganisationen haben RDF-Diagramme weitgehend übernommen.
Zunehmend gewinnen RDF-Graphs als Grundlage für intelligente Anwendungen an Bedeutung. Viele LLMs werden bereits mit RDF-Graph-Repräsentationen öffentlicher Datensätze trainiert, wie z. B. dem offenen Wissensgraphen DBpedia.
Erste Schritte mit Graphdatenbanken und Graphanalysen
Oracle macht es einfach, Diagrammtechnologien einzuführen. Oracle AI Database und Oracle Autonomous AI Database umfassen eine integrierte Graphdatenbank sowie eine Graphanalyse-Engine. Damit können Anwender mithilfe von Graphalgorithmen, Pattern-Matching-Abfragen und Visualisierungen tiefere Erkenntnisse aus ihren Daten gewinnen. Zudem sind Graphen ein integraler Bestandteil der konvergenten Oracle Database, die multimodale, Multi-Workload- und Mandantenanforderungen in einer einzigen Datenbank-Engine unterstützt. Oracle Graph unterstützt sowohl Property Graph als auch RDF Graph Modelle innerhalb einer Datenbank und ermöglicht Graphanalysen mithilfe von SQL.
Auch wenn alle Graphdatenbanken hohe Performance versprechen, überzeugen die Graphlösungen von Oracle durch leistungsstarke Abfrageperformance und Algorithmen sowie durch die enge Integration in die Oracle AI Database. Dadurch können Entwickler Graphanalysen nahtlos in bestehende Anwendungen integrieren und gleichzeitig von der standardmäßig bereitgestellten Skalierbarkeit, Konsistenz, Wiederherstellung, Zugriffskontrolle und Sicherheit der Datenbank profitieren. Oracle AI Database ist die Graphdatenbank für den Unternehmenseinsatz.
Wenn es darum geht, Beziehungen zwischen Personen, Orten, Ereignissen und Objekten in einem Datensatz zu verstehen, gibt es kein besseres Tool als eine Graphdatenbank. Besonders deutlich zeigt sich dies bei der zunehmenden Nutzung dieser Datenbanken in modernen KI-Systemen. Durch die Darstellung von Daten als Knoten und Kanten ermöglichen Graphdatenbanken KI-Systemen, diese Beziehungen effizienter zu durchlaufen und zu analysieren. Dies führt zu tieferen Erkenntnissen und fundierteren Entscheidungen. In den kommenden Jahren werden Graphdatenbanken weiter an Bedeutung gewinnen, da KI und KI-Agenten in immer mehr Implementierungen bei Unternehmen und Regierungsbehörden eine zentrale Rolle einnehmen.

Was ist der beste Ort für rechenintensive Abfragen? Eine Hyperscale-Cloud mit der Performance und den KI-Funktionen, die Sie benötigen, um komplexe, vernetzte Daten optimal auszuschöpfen.
Häufig gestellte Fragen zur Graphdatenbank
Wofür eignen sich Graphdatenbanken?
Graphdatenbanken sind darauf ausgelegt, Datenpunkte zu speichern und abzufragen, indem sie diese als Knoten und Kanten darstellen. Dadurch lassen sich Muster und Beziehungen innerhalb der Daten sichtbar machen. Aus diesem Grund eignen sie sich besonders gut für stark vernetzte Daten in Anwendungen wie sozialen Netzwerken, Empfehlungssystemen und der Betrugserkennung.
Werden Graphdatenbanken für KI eingesetzt?
Graphdatenbanken werden häufig in KI-Anwendungen eingesetzt, da sie Beziehungen in komplexen, vernetzten Daten effizient abfragen können. Dies unterstützt KI-Systeme im Betrieb von Empfehlungssystemen und der Erstellung von Wissensgraphen und ermöglicht semantische Erkenntnisse, die das Verständnis von Texten oder anderen Inhalten verbessern.
Sind Graphdatenbanken dasselbe wie relationale Datenbanken?
Graphdatenbanken und relationale Datenbanken unterscheiden sich grundlegend in ihrem Ansatz zur Speicherung und Verwaltung von Datenbeziehungen. Relationale Datenbanken nutzen Tabellen und Fremdschlüssel, um Beziehungen zwischen Datenobjekten herzustellen. Dies kann bei stark vernetzten Daten häufig zu komplexen Joins führen. Graphdatenbanken hingegen betrachten Daten als Knoten und Kanten. Dadurch können Beziehungen effizienter durchlaufen und abgefragt werden. Sie eignen sich daher besonders für Anwendungen mit komplexen, stark vernetzten Daten, wie z. B. soziale Netzwerke, Empfehlungssysteme im Einzelhandel oder Betrugserkennungssysteme.