Qu’est-ce qu’une base de données orientée graphe ?
Jeffrey Erickson | Senior Writer | 9 janvier 2026

La manière dont les bases de données orientées graphe révèlent les liens entre personnes, lieux et événements en fait une ressource précieuse pour de nombreux cas d’usage, notamment la cartographie, les recommandations de produits et la détection des fraudes. Plus récemment, les systèmes d’IA se sont mis à utiliser les graphes pour apporter davantage de contexte et de finesse aux résultats. Voyons comment fonctionnent les bases de données orientées graphe et comment tirer le meilleur parti de leurs capacités uniques.
Qu’est-ce qu’une base de données orientée graphe ?
Une base de données orientée graphe est conçue pour stocker et interroger des données complexes et interconnectées. Elle fonctionne en stockant et en représentant les données sous forme de nœuds, ou entités, et d’arêtes, ou relations. Cette représentation en graphe permet aux utilisateurs d’exécuter des analyses de graphes qui les aident à identifier et explorer des relations complexes entre entités de données.
Il existe de nombreuses bases de données orientées graphe sur le marché. Certaines, telles que Neo4j, sont des bases de données dédiées qui ne gèrent que des données de graphe, tandis que d’autres, comme Oracle AI Database, sont des bases de données d’entreprise multimodèles prenant en charge de nombreux modèles de données, dont les graphes. Contrairement aux bases de données relationnelles traditionnelles, qui stockent les données dans des tables et utilisent des jointures pour établir des relations, les bases de données orientées graphe stockent ces relations comme un élément fondamental de la base, ce qui les rend directement disponibles pour l’interrogation et l’exploration à l’aide de langages tels que Cypher, Gremlin, PGQL et SQL.
Une base de données orientée graphe est idéale pour mettre au jour des relations complexes et dynamiques entre entités de données. Cela explique leur popularité pour des cas d’usage comme les systèmes de routage et de logistique, où de multiples facteurs entrent en jeu pour définir un itinéraire optimal, ou les réseaux sociaux, où une vue du maillage complexe des connexions entre utilisateurs, groupes et centres d’intérêt est nécessaire pour formuler des recommandations. De plus, les systèmes d’IA tirent parti des bases de données orientées graphe pour produire des résultats plus opportuns, pertinents et nuancés grâce à l’essor des architectures RAG en graphes.
Points à retenir
- Les bases de données orientées graphe offrent un moyen d’explorer les relations et dépendances entre points d’un jeu de données.
- En stockant les données sous forme de nœuds et d’arêtes, elles permettent une navigation et une récupération rapides des données connectées.
- Les bases de données orientées graphe sont plébiscitées pour de nombreux cas d’usage, notamment les applications du Web sémantique, la détection des fraudes, les réseaux sociaux et les systèmes de recommandation pour le commerce de détail ou le divertissement.
- Les systèmes d’IA, de plus en plus populaires, utilisant des architectures RAG en graphes pour obtenir des résultats plus nuancés et précis, reposent sur des bases de données orientées graphe.
Ce qu’il faut savoir sur les bases de données orientées graphe
Les bases de données orientées graphe utilisent des modèles de graphe pour représenter les liens dans les données. Elles permettent d’exécuter ce que l’on appelle des « requêtes de parcours » qui, en essence, traversent un jeu de données pour trouver des connexions entre points de données. La base applique ensuite des algorithmes de graphe pour identifier des motifs, des chemins, des communautés, des influenceurs, des points uniques de défaillance et d’autres relations. La force des graphes réside dans leur capacité à relier des sources de données disparates pour apporter de nouvelles perspectives, même dans des jeux de données très volumineux et hétérogènes.
Les algorithmes de graphe sont spécialement conçus pour analyser les relations et comportements au sein des données d’un graphe, ce qui permet de révéler des liens difficiles, voire impossibles, à détecter avec d’autres méthodes. Par exemple, ils peuvent identifier les individus ou éléments les plus connectés dans des réseaux sociaux ou des processus métier, et faire ressortir des communautés, des anomalies, des motifs récurrents et des chemins reliant des personnes ou des transactions liées.
Pour parvenir à cette compréhension, les algorithmes explorent les chemins et les distances entre les sommets, c’est-à-dire les points de données représentant des entités dans un jeu de données, ainsi que leur importance et leur regroupement. Pour déterminer l’importance, ils examinent souvent les arêtes entrantes, le poids des sommets voisins et d’autres indicateurs. Les bases de données orientées graphe stockent ces relations comme des données aux côtés des nœuds eux-mêmes, ce qui permet une navigation et une récupération rapides des données connectées. Elles offrent également une certaine flexibilité de schéma, permettant au modèle de données d’évoluer au rythme des changements de relations.
Comment fonctionnent les bases de données orientées graphe ?
Les bases de données orientées graphe stockent l’information sous forme d’un réseau de nœuds représentant des entités, comme des comptes ou des transactions, et d’arêtes représentant les relations qui connectent les nœuds. Lorsqu’on interroge la base de données, elle parcourt ces arêtes prédéfinies d’un nœud à l’autre pour découvrir des motifs et des chemins au sein des données.
L’illustration ci-dessous propose un exemple simple d’une base de données orientée graphe en action. Elle représente visuellement le jeu « Six Degrees of Kevin Bacon », qui consiste à établir des connexions entre l'acteur Kevin Bacon et un autre acteur via une chaîne de films en commun. Cet accent mis sur les relations fait de ce jeu un moyen idéal pour illustrer l’analyse de graphes.
Imaginez un jeu de données avec deux catégories de nœuds : tous les films réalisés au cours de la carrière de Kevin Bacon et tous les acteurs apparaissant dans ces films. Ensuite, grâce à la technologie des graphes, nous lançons une requête pour relier Kevin Bacon à l'icône du Muppet Show « Peggy La cochonne » Le résultat serait le suivant :
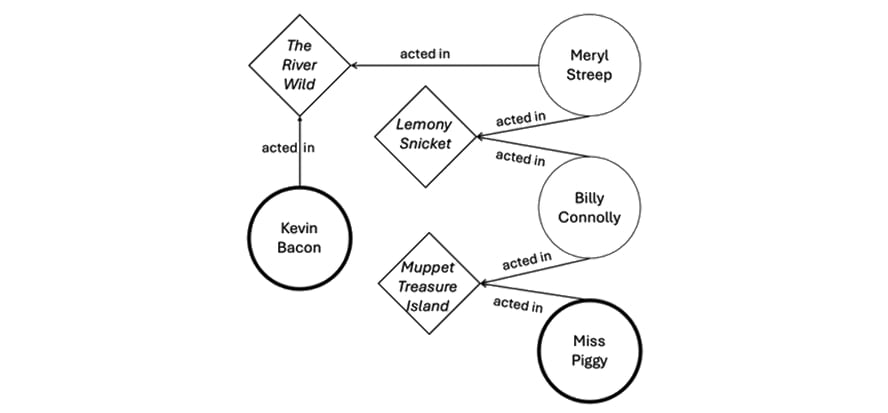
Dans cet exemple, les nœuds (sommets) disponibles sont à la fois des acteurs et des films, et les relations (arêtes) ont le statut « a joué dans ». À partir de ces éléments, la requête renvoie les résultats suivants :
- Kevin Bacon a joué dans « La Rivière sauvage » avec Meryl Streep.
- Meryl Streep a joué dans « Les désastreuses Aventures des orphelins Baudelaire » de Lemony Snicket avec Billy Connolly.
- Billy Connolly a joué dans « L’Île au trésor des Muppets » avec Peggy La cochonne.
Avec les bases de données orientées graphe, vous pouvez interroger de nombreuses relations différentes dans cet exemple, telles que :
- « Quelle est la chaîne la plus courte pour relier Kevin Bacon à Peggy La Cochonne? »
R : Analyse du plus court chemin, comme dans le jeu des Six Degrés présenté ci-dessus. - « Qui a travaillé avec le plus grand nombre d’acteurs ? »
R : La centralité de degré permet d’identifier l’acteur ayant le plus grand nombre de co-distributions. - « Quelle est la distance moyenne entre Kevin Bacon et tous les autres acteurs ? »
R : La centralité de proximité peut être utilisée pour montrer le haut niveau d’interconnexion entre les acteurs de l’industrie du cinéma.
Bien sûr, cet exemple est plus ludique que la plupart des usages de l’analyse de graphes. Toutefois, cette approche fonctionne pour quasiment toutes les données, dès lors qu’un grand nombre d’enregistrements présentent une connectivité naturelle. Parmi les usages les plus courants de l’analyse de graphes figurent l’analyse des réseaux sociaux et de communication, du trafic et de l’usage des sites Web, ainsi que des transactions et comptes financiers.
Bases de données orientées graphe et graphes
Pour créer un graphe, vous définissez le modèle de données en identifiant les nœuds et les arêtes, puis vous insérez des données dans la base de données orientée graphe à l’aide d’un langage de requête, tel que SQL ou PGQL d’Oracle, ou d’outils open source, comme Cypher ou Gremlin.
Bases de données orientées graphe et analyse de graphes
Les bases de données permettent l’analyse de graphes en prenant en charge des algorithmes qui parcourent les données de graphe pour identifier des motifs et des relations, comme le parcours en largeur (BFS) et le parcours en profondeur (DFS). De plus, les bases de données orientées graphe incluent souvent des fonctions intégrées pour l’analyse de graphes, comme les mesures de centralité et la détection de communautés. Certaines bases de données permettent aux utilisateurs de supprimer, regrouper, développer et se focaliser rapidement sur des sommets et des arêtes afin de modifier une visualisation et d’explorer les relations au sein de données de graphe complexes.
Avantages des bases de données orientées graphe
Parce que les bases de données orientées graphe mettent l’accent sur les relations entre points de données, elles favorisent une analyse efficace des relations complexes et permettent d’obtenir des insights plus riches avec beaucoup moins d’efforts. Les avantages sont les suivants :
- Meilleure analyse des réseaux : Les graphes permettent d’identifier rapidement les nœuds qui génèrent le plus d’activité ou d’influence, ou encore de repérer les points faibles d’un réseau, ce qui aide à analyser l’état du réseau ou de la communauté.
- Analyse en moins d'une seconde : Les bases de données orientées graphe stockent explicitement les relations, de sorte que les requêtes et algorithmes s’appuient sur cette connectivité entre sommets pour s’exécuter en moins d'une seconde, plutôt qu’en heures ou en jours avec une base relationnelle traditionnelle qui devrait effectuer d’innombrables jointures pour parvenir au même résultat.
- Large éventail de cas d’usage : Les graphes vous permettent d’explorer et de découvrir des connexions et des motifs au sein, par exemple, des réseaux sociaux, des données de capteurs IoT, des data lakes et des data warehouses. Ils peuvent analyser rapidement des données de transactions complexes pour de multiples cas d’usage métier, notamment la détection des fraudes bancaires, la découverte de dépendances dans les processus de fabrication, et les recommandations dans les systèmes de retail.
Quand est-il judicieux d'utiliser les bases de données orientées graphe ?
La capacité à comprendre rapidement les relations et connexions entre des personnes, des lieux, des événements, des flux financiers et bien d’autres points de données est essentielle pour un large éventail d’activités commerciales et gouvernementales. Pour comprendre pourquoi, examinons quelques exemples.
Cas d’usage des bases de données orientées graphe
Les bases de données orientées graphe sont utilisées dans un grand nombre de secteurs, avec comme fil conducteur l’importance des relations entre les points de données. Parmi les cas d’usage, citons :
-
Analyser les réseaux sociaux : Les réseaux sociaux constituent un cas d’usage idéal car ils impliquent de nombreux nœuds (comptes utilisateurs) et des connexions multidimensionnelles (interactions dans de multiples directions). Une analyse de graphe d’un réseau social peut déterminer, par exemple, le niveau d’activité des utilisateurs (nombre de nœuds). Quels utilisateurs ont le plus d'influence ? (densité des connexions). Qui a le plus d'engagement bidirectionnel ? (direction et densité de connexions). Cependant, ces informations sont inutiles si des bots les ont biaisés.
Les réseaux sociaux s’efforcent d’éliminer les comptes créés par des bots, car ils impactent l’expérience utilisateur globale. Heureusement, l’analyse de graphes peut fournir un excellent moyen d’identifier et de filtrer les robots. Dans un cas d’usage réel, l’équipe Oracle a utilisé Oracle Marketing Cloud pour évaluer la publicité sur les réseaux sociaux et l’engagement, notamment afin d’identifier les bots. Le comportement le plus fréquent de ces bots consistait à republier les comptes cibles, gonflant ainsi artificiellement leur popularité. Une simple analyse de motifs a mis en évidence le nombre de republications et la densité des connexions avec les voisins. Les comptes naturellement populaires présentaient des relations avec leurs voisins différentes de celles observées pour les comptes pilotés par des bots.
Cette image montre des comptes véritablement populaires.
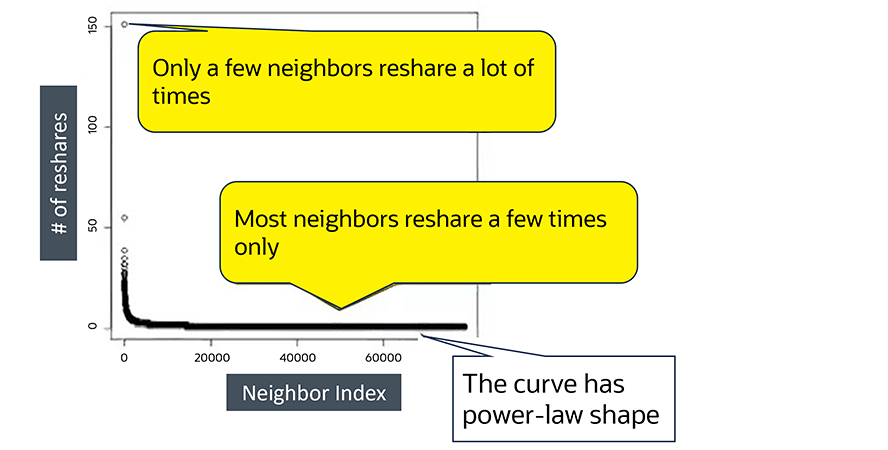 Sur une courbe simple représentant de vrais comptes de réseaux sociaux, la plupart des voisins repartagent le contenu quelques fois, selon une forme de distribution en loi de puissance.
Sur une courbe simple représentant de vrais comptes de réseaux sociaux, la plupart des voisins repartagent le contenu quelques fois, selon une forme de distribution en loi de puissance.Et cette image illustre le comportement d’un compte géré par un robot.
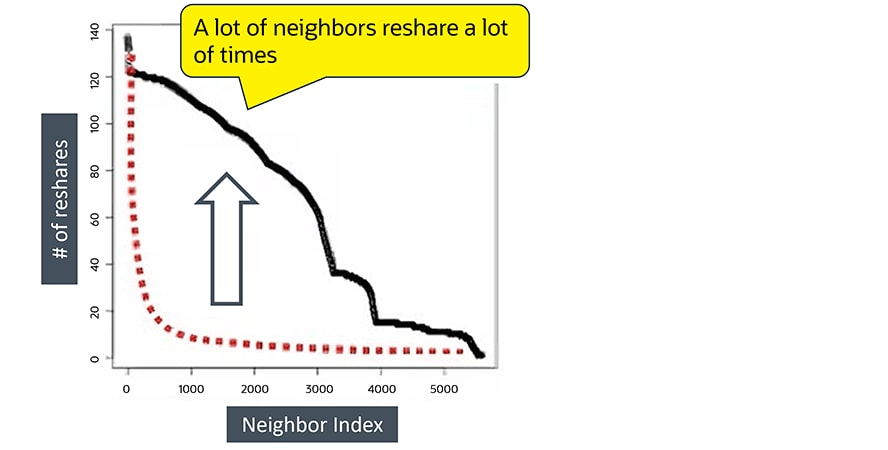 Sur une courbe simple illustrant l’activité de comptes bots, on repère un compte bot par le nombre plus élevé de voisins qui repartagent à plusieurs reprises.
Sur une courbe simple illustrant l’activité de comptes bots, on repère un compte bot par le nombre plus élevé de voisins qui repartagent à plusieurs reprises.Une fois qu’on a distingué, grâce à l’analyse de graphes, un motif naturel d’un motif lié aux bots, il suffit de filtrer ces comptes, tout en pouvant approfondir pour examiner les relations entre les bots et les comptes republiés. Pour vérifier que ce processus de détection de robots était précis, les comptes signalés ont été vérifiés après un mois. Les résultats furent les suivants :
- Suspendu : 89 %
- Supprimé : 2,2 %
- Toujours actif : 8,8 %
Le pourcentage extrêmement élevé de comptes sanctionnés (91,2 %) a démontré la précision de l’identification des motifs. L’identification de motifs complexes aurait pris beaucoup plus de temps dans une base tabulaire standard, mais avec l’analyse de graphes, c’est possible rapidement.
Traquer la fraude à la carte bancaire : Les bases de données orientées graphe sont devenues un outil puissant du secteur financier pour détecter la fraude. Malgré les avancées technologiques, comme l’utilisation de puces embarquées dans les cartes, la fraude peut encore se produire de plusieurs façons. Des dispositifs de skimming peuvent dérober des informations à partir des bandes magnétiques, une technique couramment utilisée dans les lieux qui n’ont pas encore installé de lecteurs de puce. Une fois que ces données sont stockées, elles peuvent être chargés sur une carte contrefaite pour effectuer des achats ou retirer de l’argent.
L’identification des motifs constitue souvent la première ligne de défense en matière de détection de fraude. Les modèles d’achat attendus sont basés sur l’emplacement, la fréquence, les types de magasins et autres éléments qui correspondent à un profil utilisateur. Lorsqu’un comportement semble anormal, par exemple si une personne qui reste la plupart du temps dans la région de San Francisco effectue un achat en pleine nuit en Floride, le système le signale comme potentiellement frauduleux. La puissance de calcul nécessaire est considérablement réduite grâce à l’analyse de graphes, qui excelle à établir des motifs entre les différents nœuds. Dans ce cas, les catégories de nœuds sont définies comme suit : comptes (détenteurs de carte), lieux d’achat, catégories d’achat, transactions et terminaux. Il est facile d’identifier des schémas de comportement naturels ; par exemple, au cours d’un mois donné, une personne peut :
- Acheter de la nourriture pour animaux (catégorie d’achat) dans différentes animaleries (terminaux)
- Payer des restaurants le week-end (métadonnées de transaction) dans une région donnée (lieux d’achat)
- Acheter du matériel de réparation (catégorie d’achat) dans un magasin local (lieu du compte, lieu d’achat)
La détection des fraudes est généralement gérée grâce au machine learning,, mais l’analyse de graphes peut contribuer à créer un processus plus précis et plus efficace. En se focalisant sur les relations, les résultats sont devenus des prédicteurs efficaces pour identifier et signaler les enregistrements frauduleux.
Traquer le blanchiment d’argent : Les bases de données orientées graphe aident aussi à détecter des fraudes plus sophistiquées. Conceptuellement, le blanchiment d’argent est simple : les fraudeurs font circuler de l'argent sale pour le mélanger avec des fonds légitimes afin de le transfromer en actifs tangibles. Plus précisément, un transfert circulaire consiste pour un criminel à s’envoyer d’importantes sommes d’argent obtenu frauduleusement, tout en le dissimulant via une longue série de virements valides entre des comptes « normaux » créés avec des fausses identités partageant généralement des informations similaires. Ce qui fait de l’analyse de graphes un excellent moyen de mettre au jour leur origine frauduleuse. Pour faciliter la détection de fraude, un établissement financier peut créer un graphe à partir des transactions entre comptes. Une fois le graphe créé, une simple requête permet d’identifier tous les clients dont les comptes s’envoient de l’argent entre eux et qui partagent des informations similaires, comme des e-mails, des adresses et des numéros de téléphone.
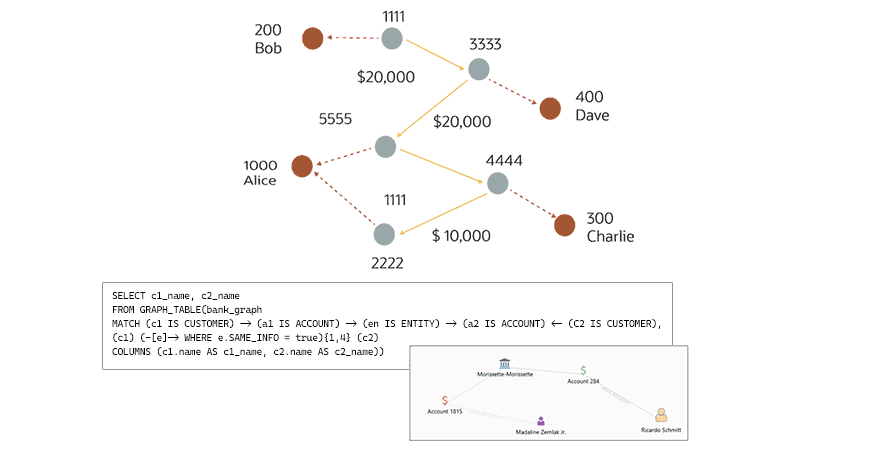 Schéma illustrant une requête de base de données orientée graphe pour la détection du blanchiment d'argent, avec une carte visuelle des clients et comptes reliés par des transferts financiers et le code SQL correspondant.
Schéma illustrant une requête de base de données orientée graphe pour la détection du blanchiment d'argent, avec une carte visuelle des clients et comptes reliés par des transferts financiers et le code SQL correspondant.Cet exemple montre comment une simple requête dans une base de données orientée graphe peut aider à détecter le blanchiment en trouvant tous les clients dont les comptes s’envoient des fonds entre eux et partagent des informations similaires.
L’avenir des bases de données orientées graphe
Les bases de données orientées graphe et les techniques associées ont évolué au rythme de la hausse des besoins en puissance de calcul et des volumes de données au cours de la dernière décennie. Il apparaît de plus en plus clairement qu’elles deviendront un outil clé pour analyser un monde nouveau de relations de données complexes. À mesure que les entreprises et organisations renforcent leurs capacités data et analytiques, la faculté d’extraire des insights de plus en plus complexes fait des bases de données orientées graphe un indispensable pour répondre aux enjeux d’aujourd’hui et réussir demain.
Comment choisir la base de données orientée graphe adaptée à vos besoins ?
Deux modèles de bases de données orientées graphe sont populaires : les graphes de propriétés et les graphes RDF, également appelés graphes de connaissances. Pour choisir le modèle adapté, retenez que le graphe de propriétés est centré sur l’analyse et l’interrogation, tandis que le graphe RDF met l’accent sur l’intégration des données. Les deux types de graphes sont constitués d'une collection de points (sommets) et des connexions entre ces points (arêtes). Les graphes de connaissances, qui représentent le sens et le contexte des relations identifiées dans les données de graphe, prennent une importance croissante pour l’intelligence artificielle.
Graphes de propriétés : Ils servent à modéliser les relations entre les données, permettant l’interrogation et l’analyse fondées sur ces relations. Un graphe de propriétés comporte des sommets contenant des informations détaillées sur un sujet et des arêtes indiquant les relations entre ces sommets. Les sommets et les arêtes peuvent avoir des attributs, appelés propriétés, qui leur sont associés.
Cet exemple représente un ensemble de collègues et leurs relations sous forme de graphe de propriétés. Nous montrons comment des collègues collaborent entre eux et, malheureusement, entrent aussi en conflit. On peut également indiquer les propriétés de ces collègues, comme leurs rôles, leurs villes de résidence, s’ils travaillent à distance, et les informations de département.
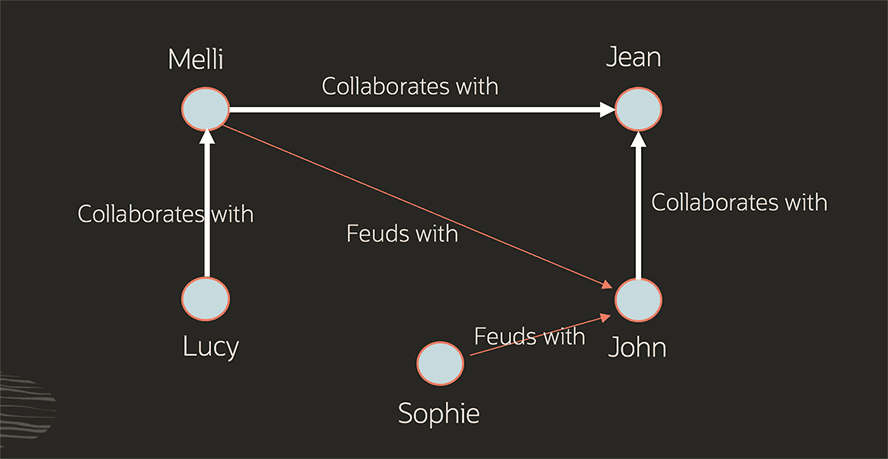
Grâce à leur polyvalence, les graphes de propriétés sont utilisés dans divers secteurs comme la finance, la fabrication, la sécurité publique et le retail.
Graphes RDF : Les graphes Resource Description Framework (RDF) répondent à un ensemble de normes du World Wide Web Consortium (W3C) conçues pour représenter des assertions et sont particulièrement adaptés à la représentation de métadonnées et de données de référence complexes. Ils sont souvent utilisés pour les données liées, l’intégration de données et, de plus en plus, les graphes de connaissances. Ils permettent de représenter des concepts complexes d’un domaine ou d’apporter une sémantique riche et des capacités d’inférence sur les données.
Dans le modèle RDF, une assertion est représentée par trois éléments : deux sommets reliés par une arête reflétant le sujet, un prédicat et l’objet de la phrase ; c’est ce que l’on appelle un triplet RDF. Un identifiant uniforme de ressource (URI) identifie chaque sommet et chaque arête. Le modèle RDF fournit un moyen de publier des données dans un format standard avec une sémantique bien définie, permettant l'échange d'informations. Les agences gouvernementales de statistiques, les entreprises pharmaceutiques et les organisations de soins de santé ont largement adopté les graphes RDF.
Les graphes RDF gagnent en popularité pour sous-tendre des applications intelligentes ; de nombreux LLM sont déjà entraînés sur des représentations en graphes RDF de jeux de données publics, comme le graphe de connaissances ouvert DBpedia.
Premiers pas avec les bases de données orientées graphe et l’analyse de graphes
Oracle facilite l'adoption des technologies graphiques. Oracle AI Database et Oracle Autonomous AI Database intègrent une base de données orientée graphe et un moteur d’analyse de graphes pour permettre aux utilisateurs de découvrir davantage de connaissances grâce aux algorithmes de graphe, aux requêtes de recherche de motifs et à la visualisation. Les graphes font partie de la base de données convergée d’Oracle, qui prend en charge des exigences multimodèles, multiworkloads et multi‑locataires, le tout dans un seul moteur de base de données. Oracle Graph prend en charge les deux modèles, Property et RDF, au sein d’une même base et supporte l’analyse de graphes avec SQL.
Même si toutes les bases de données orientées graphe revendiquent de hautes performances, les offres d’Oracle se distinguent par la rapidité des requêtes et des algorithmes, ainsi que par leur intégration étroite avec Oracle AI Database. Les développeurs peuvent ainsi ajouter facilement l’analyse de graphes à des applications existantes et bénéficier par défaut de l’évolutivité, de la cohérence, de la restauration, du contrôle d’accès et de la sécurité offerts par la base. Oracle AI Database est la base de données orientée graphe pensée pour les entreprises.
Lorsque vous souhaitez comprendre les relations entre personnes, lieux, événements et objets dans votre jeu de données, il n’y a pas de meilleur outil qu’une base de données orientée graphe. Rien ne l’illustre mieux que l’adoption de ces bases par les derniers systèmes d’IA. En représentant les données sous forme de nœuds et d’arêtes, les bases de données orientées graphe permettent aux systèmes d’IA de parcourir et d’analyser ces relations plus efficacement, pour des insights plus profonds et des décisions plus précises. À mesure que l’IA et les agents d’IA s’imposent dans toujours plus de déploiements en entreprise et dans le secteur public, les bases de données orientées graphe devraient continuer à briller.

Le meilleur endroit pour exécuter des requêtes gourmandes en ressources ? Un cloud à très grande échelle offrant les performances et capacités d’IA dont vous avez besoin pour tirer le meilleur parti de données complexes et interconnectées.
FAQ sur les bases de données orientées graphe
À quoi servent les bases de données orientées graphe ?
Les bases de données orientées graphe sont conçues pour stocker et interroger des points de données en les représentant sous forme de nœuds et d’arêtes, ce qui permet de révéler des nouvelles connaissances sur les motifs et les relations au sein des données. Elles excellent pour gérer des données très connectées dans des applications comme les réseaux sociaux, les systèmes de recommandation et la détection de fraude.
Les bases de données orientées graphe sont‑elles utilisées pour l’IA ?
Oui, elles sont couramment utilisées pour des applications d’IA, qui tirent parti de leur capacité à interroger efficacement les relations dans des données complexes et interconnectées. Cela aide l’IA à alimenter des systèmes de recommandation et à produire des graphes de connaissances, générant des perceptions sémantiques qui améliorent la compréhension de textes ou d’autres contenus par le modèle.
Les bases de données orientées graphe sont‑elles la même chose que les bases relationnelles ?
Non, les bases orientées graphe et relationnelles stockent et gèrent différemment les relations entre données. Les bases relationnelles utilisent des tables et des clés étrangères pour établir des liens entre entités de données, ce qui peut entraîner des jointures complexes lorsque les données sont fortement interconnectées. À l’inverse, les bases de données orientées graphe représentent les données sous forme de nœuds et d’arêtes, ce qui permet un parcours et une interrogation des relations plus efficaces. Elles conviennent particulièrement aux applications manipulant des données complexes et très connectées, comme les réseaux sociaux, les moteurs de recommandation pour le retail ou les systèmes de détection de fraude.